COMP2521 20T2 ♢ Hashing [0/17]
Regular array indexing is positional ([0], [1], [2], ...):
- can access items by their position in an array
- but generally don't know position for an item with key K
- we need to search for the item in the collection using K
- search can be linear (0(n)) or binary (O(log2n))
An alternative approach to indexing:
- use the key value as an index ... no searching needed
- access data for item with key K as
array[K]
COMP2521 20T2 ♢ Hashing [1/17]
❖ ... Associative Indexing | |
Difference between positional and associative indexing:
COMP2521 20T2 ♢ Hashing [2/17]
Hashing allows us to get close to associative indexing
Ideally, we would like ...
courses["COMP3311"] = "Database Systems";
printf("%s\n", courses["COMP3311"]);
but C doesn't have non-integer index values.
Something almost as good:
courses[h("COMP3311")] = "Database Systems";
printf("%s\n", courses[h("COMP3311")]);
Hash function h converts key to integer and uses that as the index.
COMP2521 20T2 ♢ Hashing [3/17]
What the h (hash) function does
Converts a key value (of any type) into an integer index.
Sounds good ... in practice, not so simple ...
COMP2521 20T2 ♢ Hashing [4/17]
Reminder: what we'd like ...
courses[h("COMP3311")] = "Database Systems";
printf("%s\n", courses[h("COMP3311")]);
In practice, we do something like ...
key = "COMP3311";
item = {"COMP3311","Database Systems",...};
courses = HashInsert(courses, key, item);
printf("%s\n", HashGet(courses, "COMP3311"));
COMP2521 20T2 ♢ Hashing [5/17]
To use arbitrary values as keys, we need ...
- set of
Key values dom(Key), each key identifies one Item
- an array (of size N ) to store
Items
- a hash function h() of type dom(
Key) → [0..N-1]
- requirement: if (x = y) then h(x) = h(y)
- requirement: h(x) always returns same value for given x
A problem: array is size
N, but
dom(Key) 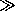 N
N
So, we also need a collision resolution method
- collision = (x ≠ y but h(x) = h(y) )
COMP2521 20T2 ♢ Hashing [6/17]
Generalised ADT for a collection of Items
Interface:
typedef struct CollectionRep *Collection;
Collection newCollection();
Item *search(Collection, Key);
void insert(Collection, Item);
void delete(Collection, Key);
Implementation:
typedef struct CollectionRep {
} CollectionRep;
COMP2521 20T2 ♢ Hashing [7/17]
For hash tables, make one change to "standard" Collection interface:
typedef struct HashTabRep *HashTable;
HashTable newHashTable(int);
void HashInsert(HashTable, Item);
Item *HashGet(HashTable, Key);
void HashDelete(HashTable, Key);
void dropHashTable(HashTable);
i.e. we specify max # elements that can be stored in the collection
COMP2521 20T2 ♢ Hashing [8/17]
Example hash table implementation:
typedef struct HashTabRep {
Item **items;
int N;
int nitems;
} HashTabRep;
HashTable newHashTable(int N)
{
HashTable new = malloc(sizeof(HashTabRep));
new->items = malloc(N*sizeof(Item *));
new->N = N;
new->nitems = 0;
for (int i = 0; i < N; i++) new->items[i] = NULL;
return new;
}
COMP2521 20T2 ♢ Hashing [9/17]
Hash table implementation (cont)
void HashInsert(HashTable ht, Item it) {
int h = hash(key(it), ht->N);
ht->items[h] = copy(it);
ht->nitems++;
}
Item *HashGet(HashTable ht, Key k) {
int h = hash(k, ht->N);
Item *itp = ht->items[h];
if (itp != NULL && equal(key(*itp),k))
return itp;
else
return NULL;
}
key() and copy() come from Item type; equal() from Key type
COMP2521 20T2 ♢ Hashing [10/17]
Hash table implementation (cont)
void HashDelete(HashTable ht, Key k) {
int h = hash(k, ht->N);
Item *itp = ht->items[h];
if (itp != NULL && equal(key(*itp),k)) {
free(itp);
ht->items[h] = NULL;
ht->nitems--;
}
}
void dropHashTable(HashTable ht) {
for (int i = 0; i < ht->N; i++) {
if (ht->items[i] != NULL) free(ht->items[i]);
}
free(ht);
}
COMP2521 20T2 ♢ Hashing [11/17]
Characteristics of hash functions:
- converts
Key value to index value [0..N-1]
- deterministic (key value k always maps to same value)
- use
mod function to map hash value to index value
- spread key values uniformly over address range
(assumes that keys themselves are uniformly distributed)
- as much as possible, h(k) ≠ h(j) if j ≠ k
- cost of computing hash function must be cheap
COMP2521 20T2 ♢ Hashing [12/17]
Basic mechanism of hash functions:
int hash(Key key, int N)
{
int val = convert key to 32-bit int;
return val % N;
}
If keys are ints, conversion is easy (identity function)
How to convert keys which are strings?
(e.g. "COMP1927" or "John")
Definitely prefer that hash("cat",N) ≠ hash("dog",N)
Prefer that hash("cat",N) ≠ hash("act",N) ≠ hash("tac",N)
COMP2521 20T2 ♢ Hashing [13/17]
Universal hashing uses entire key, with position info:
int hash(char *key, int N)
{
int h = 0, a = 31415, b = 21783;
char *c;
for (c = key; *c != '\0'; c++) {
a = a*b % (N-1);
h = (a * h + *c) % N;
}
return h;
}
Has some similarities with RNG. Aim: "spread" hash values over [0..N-1]
COMP2521 20T2 ♢ Hashing [14/17]
A real hash function (from PostgreSQL DBMS):
hash_any(unsigned char *k, register int keylen, int N)
{
register uint32 a, b, c, len;
len = keylen;
a = b = 0x9e3779b9;
c = 3923095;
while (len >= 12) {
a += (k[0] + (k[1] << 8) + (k[2] << 16) + (k[3] << 24));
b += (k[4] + (k[5] << 8) + (k[6] << 16) + (k[7] << 24));
c += (k[8] + (k[9] << 8) + (k[10] << 16) + (k[11] << 24));
mix(a, b, c);
k += 12; len -= 12;
}
mix(a, b, c);
return c % N;
}
COMP2521 20T2 ♢ Hashing [15/17]
Where mix is defined as:
#define mix(a,b,c) \
{ \
a -= b; a -= c; a ^= (c>>13); \
b -= c; b -= a; b ^= (a<<8); \
c -= a; c -= b; c ^= (b>>13); \
a -= b; a -= c; a ^= (c>>12); \
b -= c; b -= a; b ^= (a<<16); \
c -= a; c -= b; c ^= (b>>5); \
a -= b; a -= c; a ^= (c>>3); \
b -= c; b -= a; b ^= (a<<10); \
c -= a; c -= b; c ^= (b>>15); \
}
i.e. scrambles all of the bits from the bytes of the key value
COMP2521 20T2 ♢ Hashing [16/17]
In ideal scenarios, search cost in hash table is O(1).
Problems with hashing:
- hash function relies on size of array (⇒ can't expand)
- changing size of array effectively changes the hash function
- if change array size, then need to re-insert all
Items
- items are stored in (effectively) random order
- if size(KeySpace) size(IndexSpace), collisions inevitable
- collision: k ≠ j && hash(k,N) = hash(j,N)
- if
nitems > nslots, collisions inevitable
COMP2521 20T2 ♢ Hashing [17/17]
Produced: 9 Jul 2020
![[Diagram:Pics/assoc-indexing.png]](Pics/assoc-indexing.png)
![[Diagram:Pics/hashing-review.png]](Pics/hashing-review.png)