
See the example in the wikipedia page above.
** This is an initial draft, and it may change! A notice on the class web page will be posted after each revision, so please check class notice board frequently.
| Marks | 15 marks (14 marks towards total course mark) |
| Group | This assignment is completed in group of two |
| Due | Fri Jun 3 23:59:59 2016 Last day to submit this assignment is 11pm Friday 10 Jun, subject to late penalty of 0.25 mark per day off the ceiling. |
| Submit | Read instructions in the "Submission" section below, and follow the submission link. |
| Late Penalty |
0.25 mark per day off the ceiling. Last day to submit this assignment is 11pm Friday 10 Jun. |
In this assignment, your task is to implement simple search engines using well known algorithms like PageRank and tf-idf, simplified for this assignment, of course!. You should start by reading the wikipedia entries on these topics. I will also discuss these topics in the lecture.
The main focus of this assignment is to build a graph structure, calculate PageRank, tf-idf, etc. and rank pages based one these values. You don't need to spend time crawling, collecting and parsing weblinks for this assignment! You will be provided with a collection of "web pages" with the required information for this assignment in a easy to use format. For example, each page has two sections,
Example file url31.txt
#start Section-1
url2 url34 url1 url26
url52 url21
url74 url6 url82
#end Section-1
#start Section-2
Mars has long been the subject of human interest. Early telescopic observations
revealed color changes on the surface that were attributed to seasonal vegetation
and apparent linear features were ascribed to intelligent design.
#end Section-2
In Part-1: Graph structure-based search engine, you need to create a graph structure that represents a hyperlink structure of given collection of "web pages" and for each page (node in your graph) calculate PageRank and other graph properties. You need to create "inverted index" that provides a list of pages for every word in a given collection of pages. Your graph-structure based search engine will use this inverted index to find pages where query term(s) appear and rank these pages using their PageRank values.
In Part-2: Content-based search engine, you need to calculate tf-idf values for each query term in a page, and rank pages based on the summation of tf-idf values for all query terms. Use "inverted index" you created in Part-1 to locate matching pages for query terms.
In Part-3: Hybrid search engine, you need to combine both PageRank and tf-idf values in order to rank pages. More on this later ...
Additional files: You can submit additional supporting files, *.cand *.h, for this assignment. For example, you may implement your graph adt in files graph.c and graph.h and submit these two files along with other required files as mentioned below.
(8 marks)
You need to write a program in the file pagerank.c that reads data from a given collection of pages in the file collection.txt and builds a graph structure using Adjacency Matrix or List Representation. Using the algorithm described below, calculate PageRank for every url in the file collection.txt. In this file, urls are separated by one or more spaces or/and new line character. Add suffix .txt to a url to obtain file name of the corresponding "web page". For example, file url24.txt contains the required information for url24.
Example file collection.txt
url25 url31 url2
url102 url78
url32 url98 url33
Simplified PageRank Algorithm (for this assignment)
PageRank(d, diffPR, maxIterations)
Read "web pages" from the collection in file "collection.txt"
and build a graph structure using Adjacency List Representation
N = number of urls in the collection
For each url pi in the collection
PR(pi) = 1/N ;
End For
iteration = 0;
diff = diffPR; // to enter the following loop
While (iteration < maxIteration AND diff >= diffPR)
iteration++;
diff = 0; // reset diff for each iteration
For each url pi in the collection
PR_old = PR(pi);
sum = 0 ;
For each url pj pointing to pi (ignore self-loops and parallel edges)
sum = sum + PR(pj) / out-degree-of(pj);
End For
PR(pi) = (1-d)/N + d * sum
diff = diff + Abs(PR_old - PR(pi);
End For
End While
Your program in pagerank.c will take three arguments (d - damping factor, diffPR - difference in PageRank sum, maxIterations - maximum iterations) and using the algorithm described in this section, calculate PageRank for every url.
For example,
% pagerank 0.85 0.00001 1000
Your program should output a list of urls in descending order of PageRank values (to 8 significant digits) to a file named pagerankList.txt. The list should also include out degrees (number of out going links) for each url, along with its PageRank value. The values in the list should be comma separated. For example, pagerankList.txt may contain the following:
Example file pagerankList.txt
url102, 137, .0025881
url4, 196, .0023054
url75, 7, .0021345
Sample files for 1A, all the sample files were generated using the following command:
% pagerank 0.85 0.00001 1000
You need to write a program in the file named inverted.c that reads data from a given collection of pages in collection.txt and generates an "inverted index" that provides a list (set) of urls for every word in a given collection of pages. You need to "normalise" words by removing leading and trailing spaces and converting all characters to lowercases before inserting words in your index. In each list (set), duplicate urls are not allowed. Your program should output this "inverted index" to a file named invertedIndex.txt. The list should be alphabetically ordered, using ascending order.
Example file invertedIndex.txt
design url31 url2 url61 url25
mars url31 url25 url101
vegetation url61 url31
Write a simple search engine in file searchPagerank.c that given search terms (words) as commandline arguments, outputs (to stdout) top ten pages in descending order of PageRank. If number of matches are less than 10, output all of them. Your program must use data available in two files invertedIndex.txt and pagerankList.txt, and must derive result from them. We will test this program independently to your solutions for "A" and "B".
Example:
% searchPagerank mars design
url31
url25
(4 marks)
In this part, you need to implement a content-based search engine that uses tf-idf values of all query terms for ranking. You need to calculate tf-idf values for each query term in a page, and rank pages based on the summation of tf-idf values for all query terms. Use "inverted index" you created in Part-1 to locate matching pages for query terms.
Read the following wikipedia page that describes how to calculate tf-idf values:
For this assignment,
Write a content-based search engine in file searchTfIdf.c that given search terms (words) as commandline arguments, outputs (to stdout) top ten pages in descending order of summation of tf-idf values of all search terms (as described above). Your program must also output the corresponding summation of tf-idf along with each page, separated by a space and using format "%.6f", see example below (added on May 24).
If number of matches are less than 10, output all of them. Your program must use data available in two files invertedIndex.txt and collection.txt, and must derive result from them. We will test this program independently to your solutions for Part-1.
Example:
% searchTfIdf mars design
url25 1.902350
url31 0.434000
(3 marks)
In this part, you need to combine search results (ranks) from multiple sources (say from Part-1 and Part-2) using "Scaled Footrule Rank Aggregation" method, described below. All the required information for this method are provided below. However, if you are interested, you may want to check out this presentation on "Rank aggregation method for the web".
Let T1 and T2 are search results (ranks) obtained from Part-1 and Part-2 respectively. Let's assume S is a union of T1 and T2. A weighted bipartite graph for scaled footrule optimization (C,P,W) is defined as,

For example,
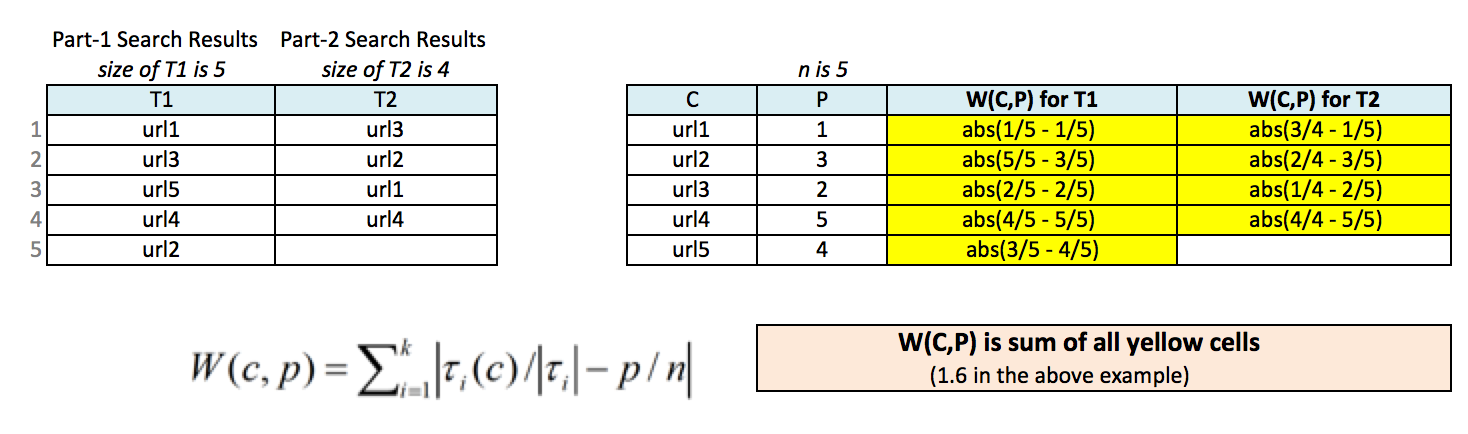
The final ranking is derived by finding possible values of position 'P' such that the scaled-footrule distance is minimum. There are many different ways to assign possible values for 'P'. In the above example P = [1, 3, 2, 5, 4]. Some other possible values are, P = [1, 2, 4, 3, 5], P = [5, 2, 1, 4, 3], P = [1, 2, 3, 4, 5], etc. For n = 5, possible alternatives are 5! For n = 10, possible alternatives would be 10! that is 3,628,800 alternatives. A very simple and obviously inefficient approach could use brute-force search and generate all possible alternatives, calculate scaled-footrule distance for each alternative, and find the alternative with minimum scaled-footrule distance. If you use such a brute-force search, you will receive maximum of 2 marks (out of 3) for Part-3. However, you will be rewarded upto 1 mark if you implement a "smart" algorithm that avoids generating unnecessary alternatives, in the process of finding the minimum scaled-footrule distance. Please document your algorithm such that your tutor can easily understand your logic, and clearly outline how you plan to reduce search space, otherwise you will not be awarded mark for your "smart" algorithm! Yes, it's only a mark, but if you try it, you will find it very challenging and rewarding.
Write a program scaledFootrule.c that aggregates ranks from files given as commandline arguments, and output aggregated rank list with minimum scaled footrule distance.
Example, file rankA.txt
url1
url3
url5
url4
url2
Example, file rankD.txt
url3
url2
url1
url4
The following command will read ranks from files "rankA.txt" and "rankD.txt" and outputs minimum scaled footrule distance (using format %.6f) on the first line, followed by the corresponding aggregated rank list.
% scaledFootrule rankA.txt rankD.txt
For the above example, there are two possible answers, with minimum distance of 1.400000. Two possible values of P with minnimum distance are:
By the way, you need to select any one of the possible values of P that has minium distance, so there could be multiple possible answers. Note that you need to output only one such list.
One possible answer for the above example, for P = [1, 4, 2, 5, 3] :
1.400000
url1
url3
url5
url2
url4
Another possible answer for the above example, P = [1, 5, 2, 4, 3] :
1.400000
url1
url3
url5
url4
url2
Your program should be able to handle multiple rank files, for example:
% scaledFootrule rankA.txt rankD.txt newSearchRank.txt myRank.txt
Additional files: You can submit additional supporting files, *.c and *.h, for this assignment.
IMPORTANT: Make sure that your additional files (*.c) DO NOT have "main" function.
For example, you may implement your graph adt in files graph.c and graph.h and submit these two files along with other required files as mentioned below. However, make sure that these files do not have "main" function.I explain below how we will test your submission, hopefully this will answer all of your questions.
You need to submit the following files, along with your supporting files (*.c and *.h):
% gcc -Wall -lm *.c -o pagerank
So we will not use your Makefile (if any). The above command will generate object files from your supporting files and the file to be tested (say pagerank.c), links these object files and generates executable file, say pagerank in the above example. Again, please make sure that you DO NOT have main function in your supporting files (other *.c files you submit).
We will use similar approach to generate other four executables (from inverted.c, searchPagerank.c, searchTfIdf.c and scaledFootrule.c).
To submit your ass2 files, goto the submission page for Ass2
This is an individual assignment. Each student will have to develop their own solution without help from other people. In particular, it is not permitted to exchange code or pseudocode. You are not allowed to use code developed by persons other than yourself. If you have questions about the assignment, ask your tutor Before submitting any work you should read and understand the following very useful guide by the Learning Centre How Not To Plagiarise. All work submitted for assessment must be entirely your own work. We regard unacknowledged copying of material, in whole or part, as an extremely serious offence. For further information, see the Course Information.
-- end --